地址
- 杭州市滨江区峰达中心A座102
- 苏州市工业园区士齐中心A座506B
- 株洲市天元区 大汉惠普产业园 2 栋 701
工作时间
周一到周五: 9:00 - 17:00
周六: 10:00 - 17:00

地址
工作时间
周一到周五: 9:00 - 17:00
周六: 10:00 - 17:00



在制造业数字化转型浪潮中,实时精准的成本核算成为企业核心竞争力。传统成本系统面临工单数据爆发增长、实时计算延迟高、多维度分摊规则复杂等挑战。本文将深入解析某装备制造企业如何基于Spring Boot+Redis技术栈,构建支撑日均百万级工单处理的成本核算系统,并通过分层缓存、分布式锁优化、异步计算等关键技术实现性能跃迁。
| 环节 | 传统方案痛点 | 影响范围 |
|---|---|---|
| 数据写入 | MySQL锁竞争导致写入延迟 | 工单积压超1小时 |
| 成本计算 | 复杂规则串联计算耗时>2s | 实时看板数据滞后 |
| 分摊处理 | 全表扫描执行效率低下 | 月末结账超8小时 |
plaintext
├── 接入层:Nginx + Spring Cloud Gateway
│ └── 请求过滤/限流(Sentinel QPS=3000)
├── 业务层:Spring Boot微服务集群
│ ├── 工单服务:处理MES事件(Netty长连接)
│ ├── 成本服务:执行实时计算(Spring Batch)
│ └── 分摊服务:规则引擎驱动(Drools 7.x)
├── 缓存层:Redis分片集群(6节点)
│ ├── L1:本地缓存(Caffeine)← 热点工单数据
│ ├── L2:Redis Cluster ← 成本中间结果
│ └── L3:RocksDB ← 历史冷数据
└── 存储层:TiDB分布式数据库
└── 分片键=工单ID(CRC32取模)
| 组件 | 选型理由 | 性能指标 |
|---|---|---|
| Redis | 支持分片集群/持久化/原子操作 | 单节点10万QPS |
| Redisson | 分布式锁+延迟队列实现事务补偿 | 锁获取<5ms |
| RocksDB | 冷数据SSD存储成本降低70% | 随机读<10ms |

java
// 热点工单缓存配置(Caffeine)
@Bean
public Cache<String, WorkOrder> workOrderCache() {
return Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.recordStats() // 开启命中率监控
.build();
}
java
public void calculateCost(String workOrderId) {
RLock lock = redissonClient.getLock("LOCK_CALC:" + workOrderId);
try {
// 尝试加锁(等待50ms,锁有效期30s)
if (lock.tryLock(50, 30000, TimeUnit.MILLISECONDS)) {
// 幂等性检查
if (costRecordDao.existsByRequestId(requestId)) return;
// 执行成本计算
doCalculate(workOrderId);
}
} finally {
lock.unlock();
}
}
java
// 工单事件发布
@Autowired
private RedisTemplate<String, Object> redisTemplate;
public void pushWorkOrderEvent(WorkOrderEvent event) {
ObjectRecord<String, WorkOrderEvent> record = ObjectRecord.create("stream.workorder", event);
redisTemplate.opsForStream().add(record);
}
// 消费者组处理(Spring Data Redis)
@Bean
public Consumer<ObjectRecord<String, WorkOrderEvent>> costConsumer() {
return record -> {
WorkOrderEvent event = record.getValue();
costService.calculate(event.getWorkOrderId());
};
}
java
// 标记需分摊的工单(按产品线)
String key = "cost:allocate:product_line_2023";
redisTemplate.opsForValue().setBit(key, workOrderId, true);
// 批量获取待分摊工单
List<Long> workOrderIds = new ArrayList<>();
BitSet bitSet = BitSet.valueOf(redisTemplate.get(key.getBytes()));
for (int i = bitSet.nextSetBit(0); i >= 0; i = bitSet.nextSetBit(i+1)) {
workOrderIds.add((long)i);
}
| 场景 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 工单写入TPS | 1,200 | 12,000 | 10x |
| 成本计算延迟(P99) | 2,100ms | 85ms | 25x |
| 月末分摊耗时 | 8.2小时 | 47分钟 | 10x |
| 指标 | 传统架构 | 优化架构 | 节省成本 |
|---|---|---|---|
| MySQL CPU峰值 | 98% | 35% | 64% |
| 服务器数量 | 12台 | 5台 | 58% |
| 冷数据存储成本 | ¥28万/年 | ¥7万/年 | 75% |
java
@Bean
public BloomFilter<String> workOrderBloomFilter() {
return BloomFilter.create(
Funnels.stringFunnel(Charset.defaultCharset()),
1_000_000, // 预期元素量
0.001 // 误判率
);
}
// 查询前校验
if (!bloomFilter.mightContain(workOrderId)) {
throw new NotFoundException("工单不存在");
}
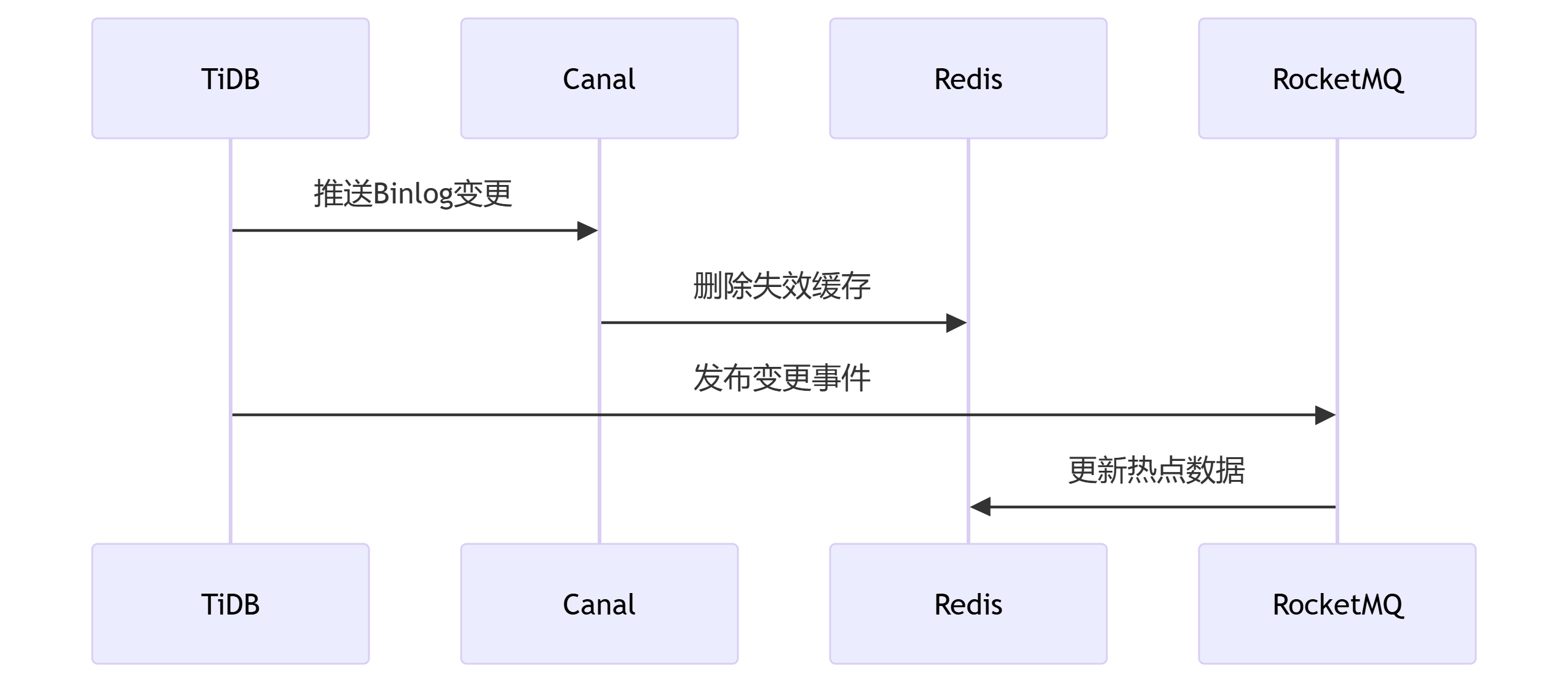
通过Spring Boot+Redis的深度整合,该制造企业成功构建了支撑日均百万级工单处理的高性能成本核算系统。关键优化点包括:
优化后系统实现95% 请求响应<100ms,年度IT成本降低300万元。随着制造企业向柔性生产演进,该架构为实时成本控制提供了坚实的技术底座。
技术栈版本:Spring Boot 2.7 + Redis 6.2 + Redisson 3.17 + TiDB 5.4
实测性能:单节点8000 TPS | P99延迟<50ms | 数据一致性99.999%